













[ad_1]

Meta is including one other Llama to its herd—and this one is aware of methods to code. On Thursday, Meta unveiled “Code Llama,” a brand new massive language mannequin (LLM) primarily based on Llama 2 that’s designed to help programmers by producing and debugging code. It goals to make software program growth extra environment friendly and accessible, and it is free for business and analysis use.
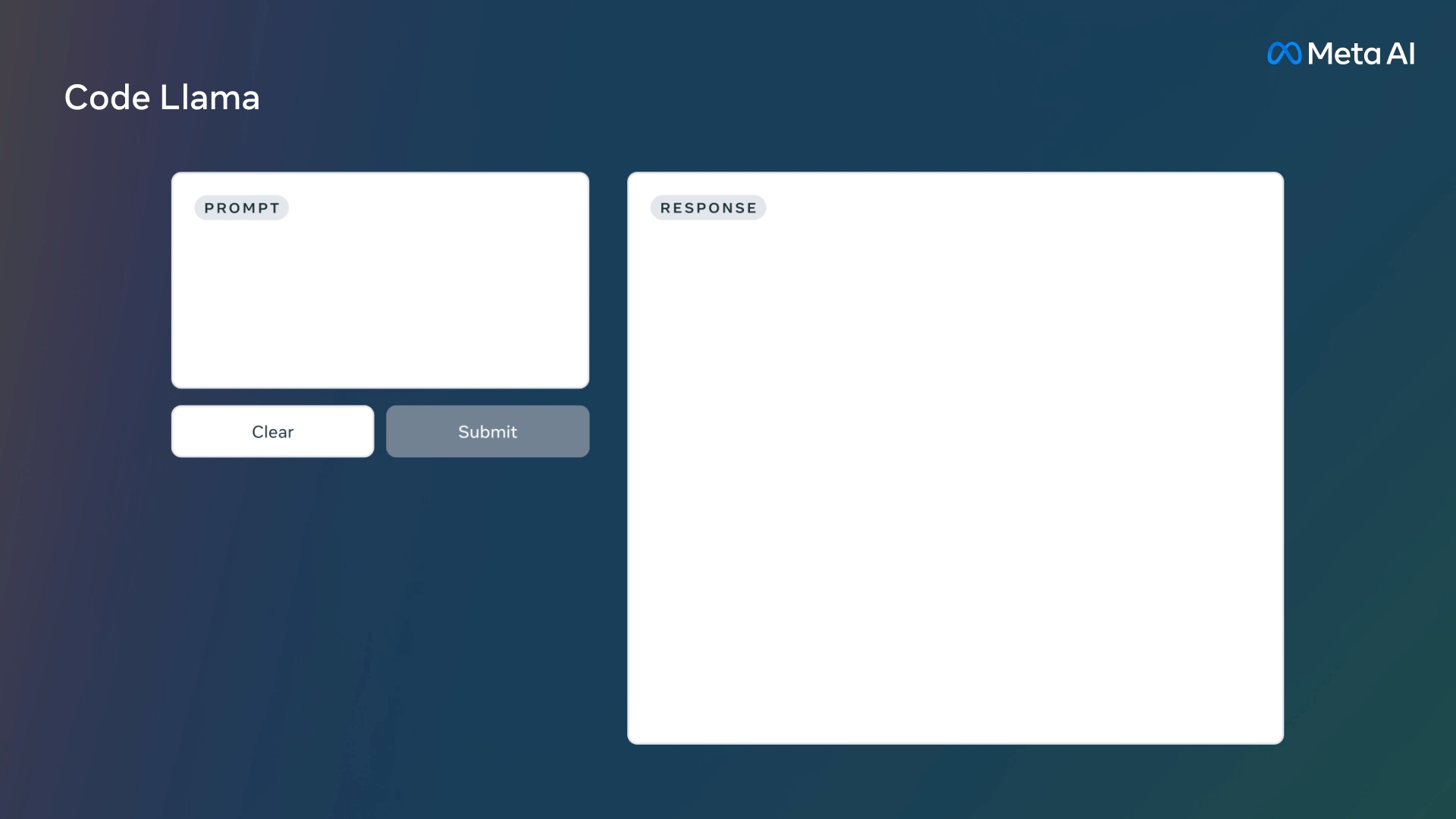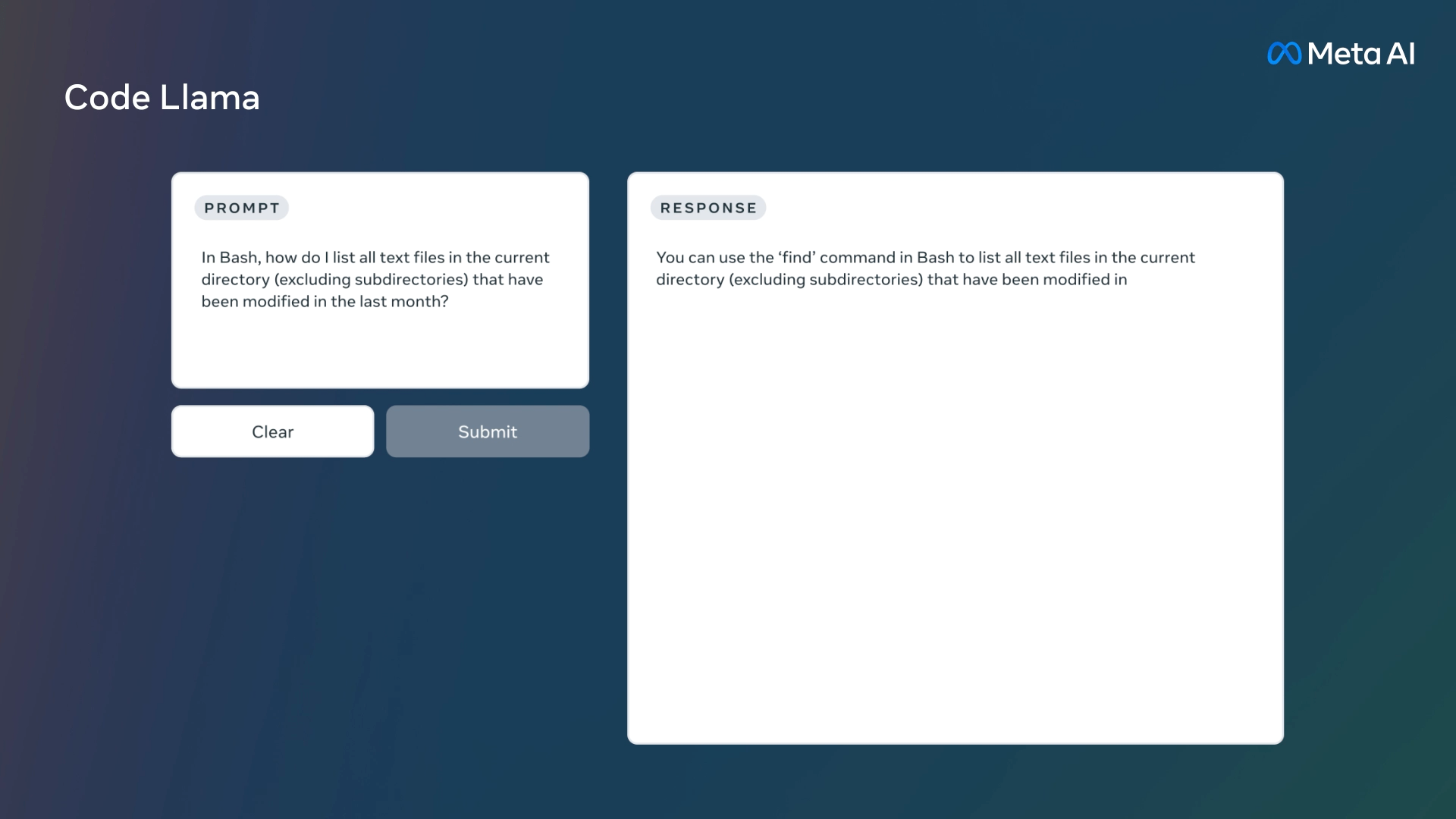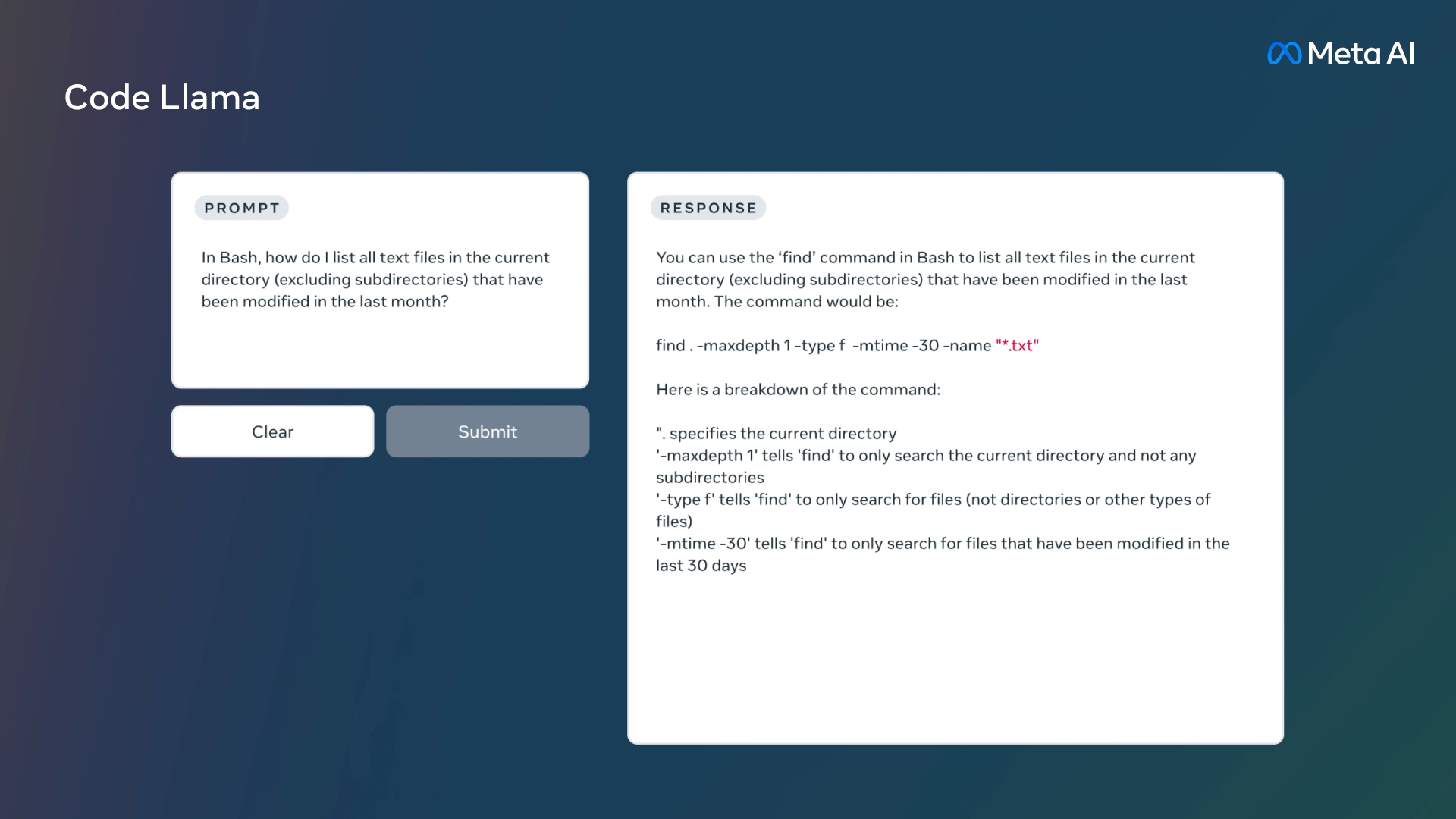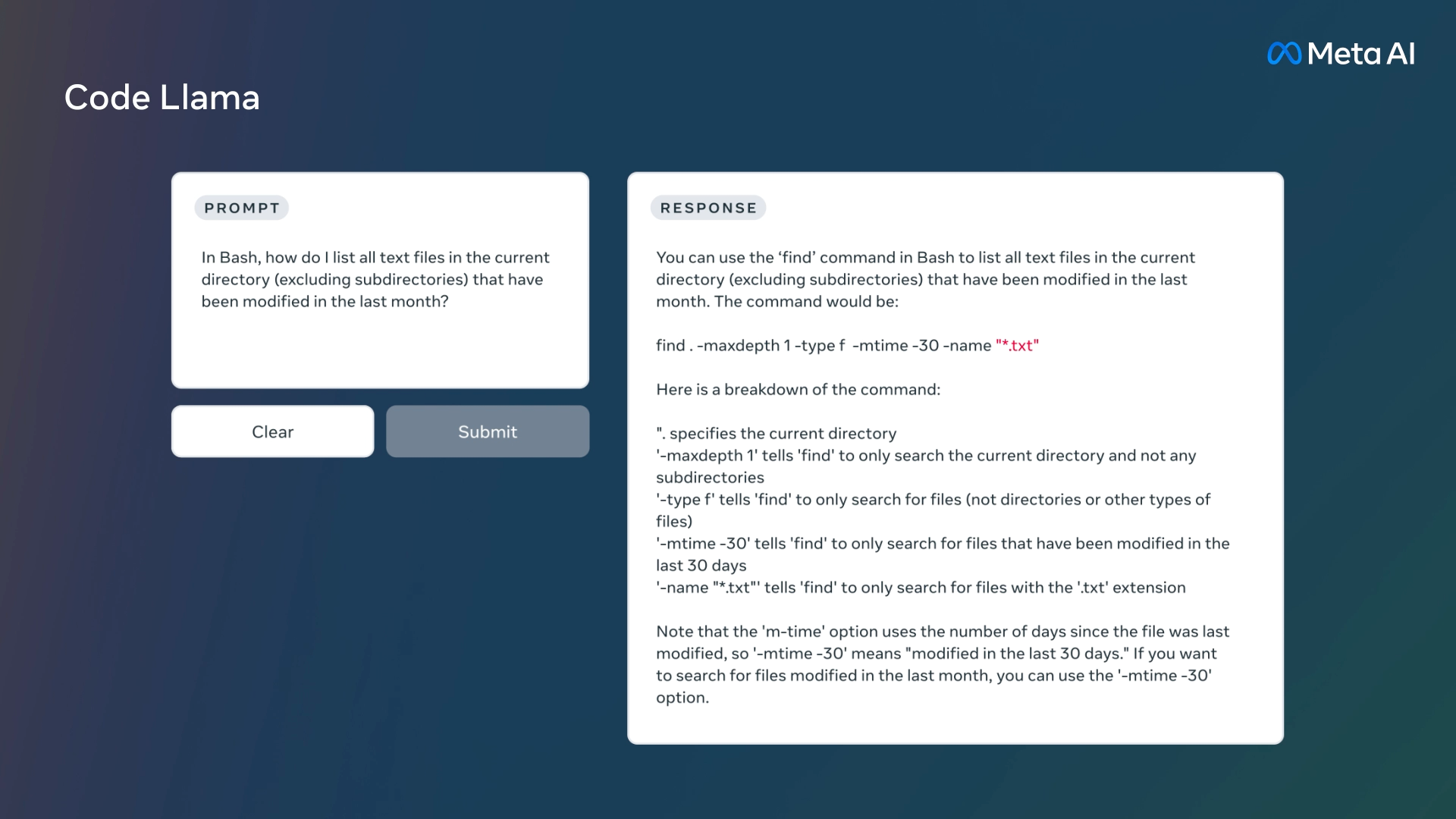
Very like ChatGPT and GitHub Copilot Chat, you’ll be able to ask Code Llama to jot down code utilizing high-level directions, equivalent to “Write me a operate that outputs the Fibonacci sequence.” Or it may help with debugging if you happen to present a pattern of problematic code and ask for corrections.
As an extension of Llama 2 (launched in July), Code Llama builds off of weights-available LLMs Meta has been creating since February. Code Llama has been particularly educated on supply code knowledge units and may function on varied programming languages, together with Python, Java, C++, PHP, TypeScript, C#, Bash scripting, and extra.
Notably, Code Llama can deal with as much as 100,000 tokens (phrase fragments) of context, which suggests it may consider lengthy packages. To check, ChatGPT usually solely works with round 4,000-8,000 tokens, although longer context fashions can be found by means of OpenAI’s API. As Meta explains in its extra technical write-up:
Except for being a prerequisite for producing longer packages, having longer enter sequences unlocks thrilling new use instances for a code LLM. For instance, customers can present the mannequin with extra context from their codebase to make the generations extra related. It additionally helps in debugging eventualities in bigger codebases, the place staying on high of all code associated to a concrete problem could be difficult for builders. When builders are confronted with debugging a big chunk of code they will cross your entire size of the code into the mannequin.
Meta’s Code Llama is available in three sizes: 7, 13, and 34 billion parameter variations. Parameters are numerical components of the neural community that get adjusted in the course of the coaching course of (earlier than launch). Extra parameters typically imply larger complexity and better functionality for nuanced duties, however in addition they require extra computational energy to function.
An illustration of Code Llama supplied by Meta.
Meta
The completely different parameter sizes provide trade-offs between pace and efficiency. Whereas the 34B mannequin is anticipated to offer extra correct coding help, it’s slower and requires extra reminiscence and GPU energy to run. In distinction, the 7B and 13B fashions are quicker and extra appropriate for duties requiring low latency, like real-time code completion, and may run on a single consumer-level GPU.
Meta has additionally launched two specialised variations: Code Llama – Python and Code Llama – Instruct. The Python variant is optimized particularly for Python programming (“fine-tuned on 100B tokens of Python code”), which is a crucial language within the AI neighborhood. Code Llama – Instruct, alternatively, is tailor-made to raised interpret person intent when supplied with pure language prompts.
Moreover, Meta says the 7B and 13B base and instruct fashions have additionally been educated with “fill-in-the-middle” (FIM) functionality, which permits them to insert code into present code, which helps with code completion.
License and knowledge set
Code Llama is out there with the similar license as Llama 2, which gives weights (the educated neural community recordsdata required to run the mannequin in your machine) and permits analysis and business use, however with some restrictions specified by an acceptable use coverage.
Meta has repeatedly acknowledged its choice for an open method to AI, though its method has acquired criticism for not being totally “open supply” in compliance with the Open Supply Initiative. Nonetheless, what Meta gives and permits with its license is much extra open than OpenAI, which doesn’t make the weights or code for its state-of-the-art language fashions accessible.
Meta has not revealed the precise supply of its coaching knowledge for Code Llama (saying it is primarily based largely on a “near-deduplicated dataset of publicly accessible code”), however some suspect that content material scraped from the StackOverflow web site could also be one supply. On X, Hugging Face knowledge scientist Leandro von Werra shared a doubtlessly hallucinated dialogue a few programming operate that included two actual StackOverflow person names.
Within the Code Llama analysis paper, Meta says, “We additionally supply 8% of our samples knowledge from pure language datasets associated to code. This dataset comprises many discussions about code and code snippets included in pure language questions or solutions.”
Nonetheless, von Werra want to see specifics cited sooner or later. “It could be nice for reproducibility and sharing data with the analysis neighborhood to reveal what knowledge sources have been used throughout coaching,” von Werra wrote. “Much more importantly it will be nice to acknowledge that these communities contributed to the success of the ensuing fashions.”
[ad_2]
Source_link